Chapter 1.2 Representing Sets and Relations in Archaeological Data using Python
Objective: Translate mathematical concepts such as sets, relations, and functions into Python data structures that can be used to organize excavation data from Tell Logika.
In the previous section, we introduced the basic concepts of sets, relations, functions, and cardinality. In this chapter, we will now implement those concepts using code. You will learn how to use Python’s built-in data types — including sets, tuples, lists, and dictionaries — to structure your excavation data. These tools will form the foundation of every dataset and analysis you build throughout this book.
1.2.1 Sets in Python
- Sets store unique, unordered elements
- Defined using curly brackets
{} or the set() function
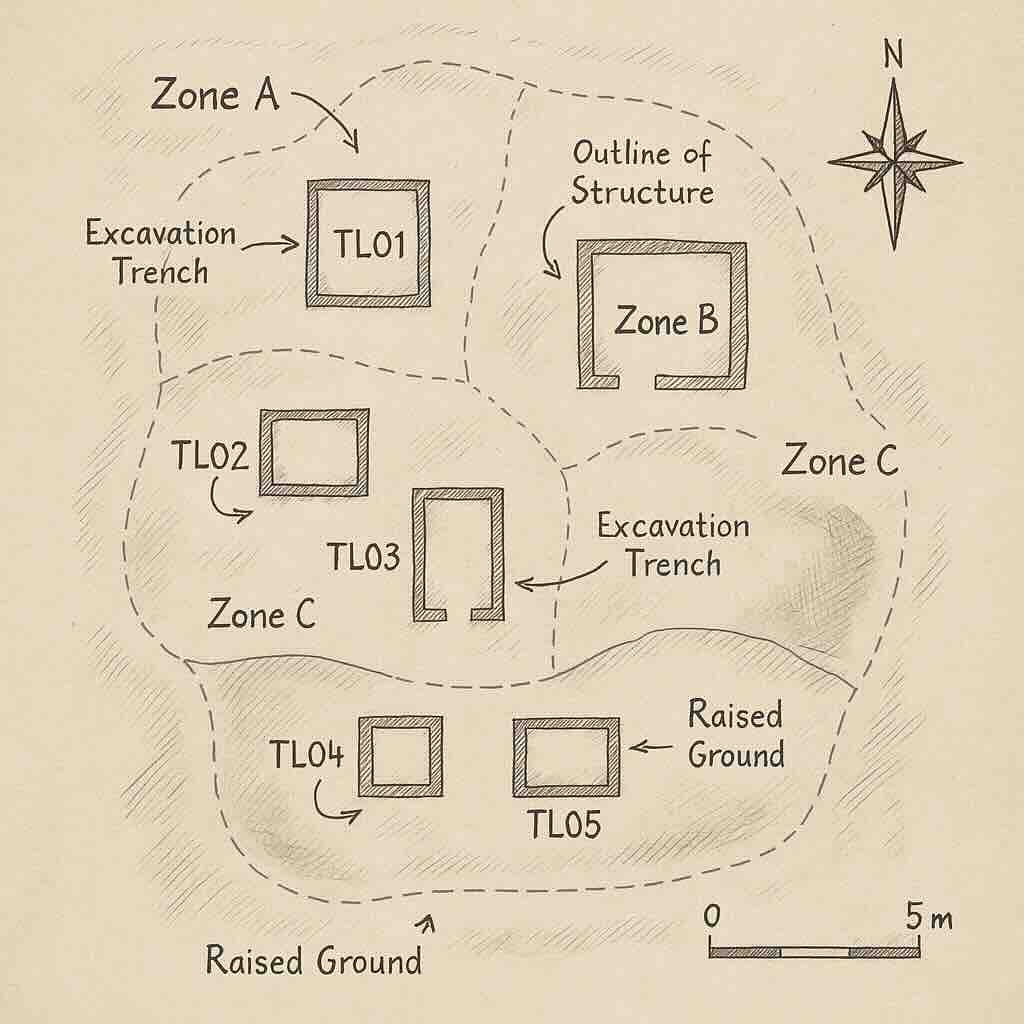
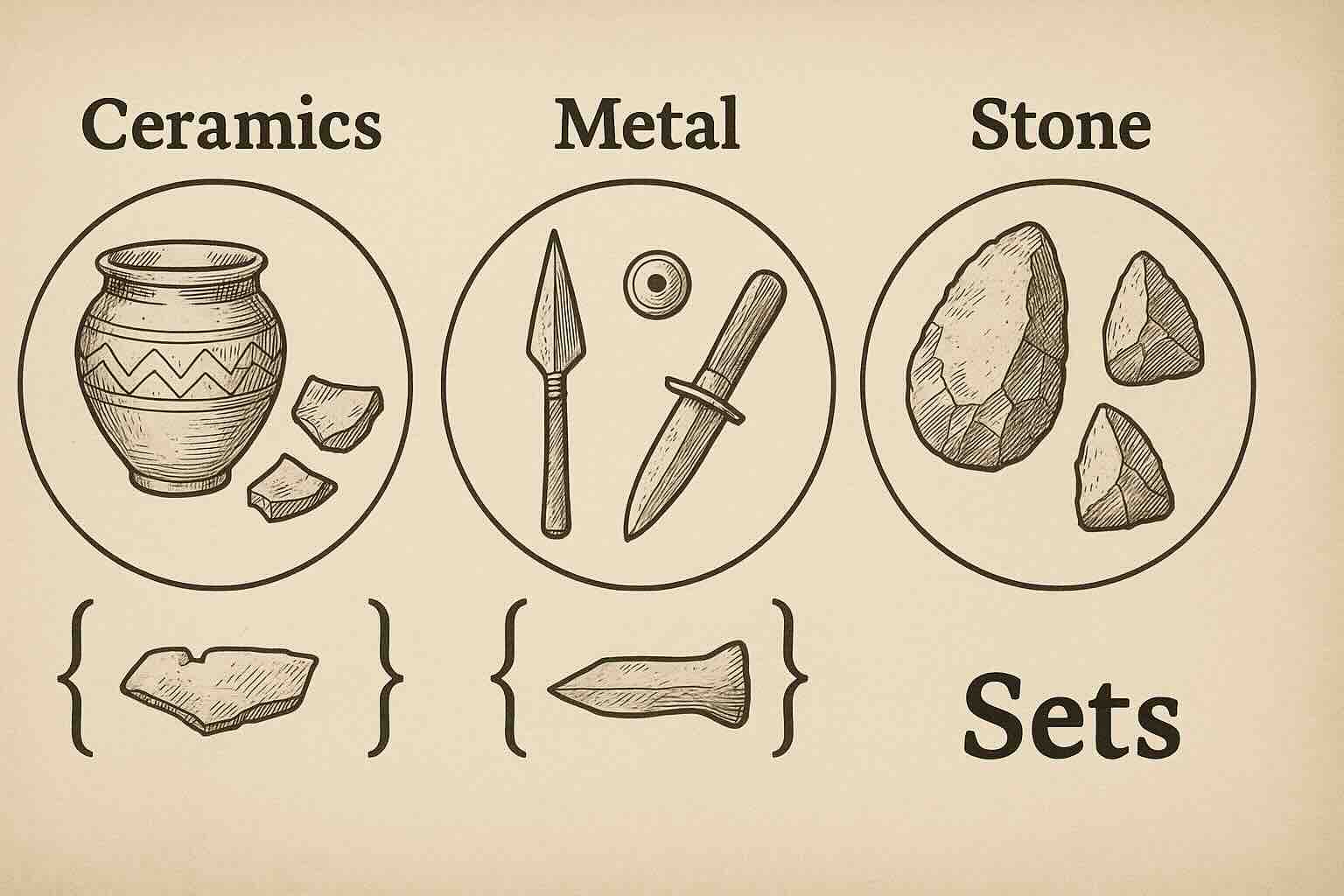
Example: A set of trench IDs where metal tools were found:
metal_trenches = {"TL01", "TL03", "TL05"}
Because sets do not allow duplicates, Python automatically ensures that each trench ID appears only once.
1.2.2 Set Operations
Python supports mathematical-style operations between sets:
A | B: Union — all items from both setsA & B: Intersection — items common to both setsA - B: Difference — items in A but not in B
Example: Let’s say we want to analyze which trenches had specific artifact types.
ceramic_trenches = {"TL01", "TL02", "TL03"}
stone_trenches = {"TL03", "TL04"}
Now apply the operations:
# Union: trenches with ceramic or stone
print(ceramic_trenches | stone_trenches) # {'TL01', 'TL02', 'TL03', 'TL04'}
# Intersection: trenches with both
print(ceramic_trenches & stone_trenches) # {'TL03'}
# Difference: trenches with ceramic only
print(ceramic_trenches - stone_trenches) # {'TL01', 'TL02'}
This is useful in archaeology for comparing artifact types between excavation areas or trench phases.
1.2.3 Tuples and Lists
Tuple: Used to store fixed pairs (e.g., trench and elevation).
elevations = [("TL01", 150), ("TL02", 160)]
Each tuple is a pair where the trench ID is linked to a measurement. Tuples are immutable, meaning they cannot be changed after being created. This is useful when storing excavation records that should remain consistent.
List: A flexible structure for ordered collections.
artifact_counts = [23, 45, 12]
This could represent artifact totals found in trenches TL01, TL02, and TL03 respectively. The order matters, but you would typically store these alongside trench names using tuples or dictionaries.
1.2.4 Storing Relations as Tuples
Tuples allow us to express pairwise relationships, such as:
trench_materials = [("TL01", "metal"), ("TL02", "ceramic"), ("TL03", "stone")]
for trench, material in trench_materials:
print(f"Trench {trench} contains {material} artifacts.")
Storing data as tuples ensures that each relationship remains tightly linked. This format mirrors rows in a spreadsheet or CSV file, making it easier to convert to a table or load into a database later.
1.2.5 Dictionaries as Functions
- A
dictionary links keys to values
- Each key maps to one value, like a mathematical function
- Dictionaries are fast and ideal for data lookup and mapping
Example: Trench → Artifact Count
artifact_totals = {
"TL01": 120,
"TL02": 85,
"TL03": 100
}
artifact_totals["TL03"] would return 100, the number of artifacts in trench TL03. Dictionaries are very useful when your data includes labels or names and you want to retrieve associated values quickly.
You might also use dictionaries to track tool types, excavation years, or radiocarbon dates by site.
1.2.6 Nested Dictionaries for Complex Data
Most archaeologists are familiar with CSV (Comma-Separated Values) files. Here’s a basic example of how data might be structured in a CSV file:
Trench, Material, Count
TL01, ceramic, 45
TL02, metal, 30
TL03, stone, 22
This format is simple and works well for flat tables. However, archaeological data can often be hierarchical — for example, grouped by region, phase, or feature.
That’s where JSON (JavaScript Object Notation) is more powerful. JSON allows us to store nested data:
site_data = {
"North": {"TL01": "metal", "TL02": "ceramic"},
"South": {"TL03": "stone"}
}
This structure helps when managing multi-layered excavation units, complex features, or site-wide comparisons.
1.2.7 Choosing the Right Structure
| Structure | Use Case |
|---|
| Set | To store unique trench or artifact types |
| Tuple | For fixed data pairs (e.g., trench and elevation) |
| List | To store sequences of values with order |
| Dictionary | For mapping keys to values like trench to count |
1.2.8 What’s Next?
In the next chapter, you’ll begin working with larger datasets — building mock excavation tables, filtering values, and loading external CSV files.
1.2.9 Quick Review
- ✅
set(): stores unique items and supports comparisons
- ✅
tuple: stores linked, fixed-size data pairs
- ✅
list: stores ordered values and supports iteration
- ✅
dict: maps labels to values for fast lookup
📘 Activity: Representing Excavation Records in Python
Scenario: You are digitizing excavation logs from Tell Logika. Your goal is to use Python to model relationships between trenches, materials, and counts.
Step-by-Step Instructions:
- Create a
set of trench IDs where metal tools were found:
metal_trenches = {"TL01", "TL03", "TL05"}
- Create a
list of tuples representing trench IDs and elevation values:
elevations = [("TL01", 150), ("TL02", 160), ("TL03", 155)]
- Create a
dictionary mapping trench ID to artifact count:
artifact_totals = {
"TL01": 120,
"TL02": 85,
"TL03": 100
}
- Print the total number of trenches recorded:
print("Total trenches:", len(artifact_totals))
- Determine which trenches had both ceramic and stone artifacts using
& (intersection):
ceramic_trenches = {"TL01", "TL02"}
stone_trenches = {"TL02", "TL03"}
print("Both ceramic and stone:", ceramic_trenches & stone_trenches)
Tips for Exploration:
- Try changing the artifact types and re-running the comparisons
- Use
print() with sorted() to see set results in order
- Add a second level to your dictionary to include artifact type
🔗 GitHub Resources: All code and examples available here